AI Assistant Tools
Overview
A summary of the various Qarbine and Generative AI integrations can be reviewed from a presentation at the February 2025 AWS Philadelphia Meetup event. See the slides for the session on "Leveraging AI Across the Application Lifecycle" on the Qarbine web site.
Qarbine can use one of several Generative AI services to answer data oriented questions and obtain embedding vectors for queries. The latter can be used to locate similar content based on comparing their vectors. Among the integrated services are:
- AWS Bedrock,
- Cohere,
- Google AI,
- Gradient,
- Jina AI,
- Hugging Face,
- Microsoft Azure AI,
- Mistral,
- Nomic,
- Open AI,
- Perplexity,
- Together AI, and
- others.
The embedding vectors from these services can be used to query a variety of modern databases. You must make sure that the models used to generate the dynamic embeddings are compatible with the one(s) used to generate the embeddings stored in the database.
Data Access AI Query Assistant
Overview
ChatGPT-like integration is available as a querying assistant dialog within the Data Source Designer. The available AI services are set by the Qarbine Administrator. This tooling can provide a variety of query guidance to assist you in retrieving your data.
Any AI service performs much better if it has context around the prompts you are asking it. With this in mind Qarbine provides information about the structure of your data. Importantly none of your underlying data is sent to the AI Assistant endpoint as part of the amplifying context. Users must still be cautious about their free form input which is sent to an AI Assistant as part of the interaction lifecycle. Consult your IT or other company department for guidance.
Choosing Your Data Context
The Data Access Query Assistant is available to help you author queries. In the Data Source Designer first choose the data of interest by selecting options from the 2 drop downs noted below. An example is shown.

Next, select the collection (or table) of interest. A simple example is shown below.

When you open a Data Source component these selections may be automatically done for you.
The general structure of the collection is shown along with cues regarding expected data types. NoSQL databases like MongoDB support nested documents and arrays as well. There is an example discussed in a section below. On the right side of the Data Source Designer toolbar click  to access the Data Access Query Assistant.
to access the Data Access Query Assistant.
Query Interactions
The initial dialog is shown below. It is movable as well.
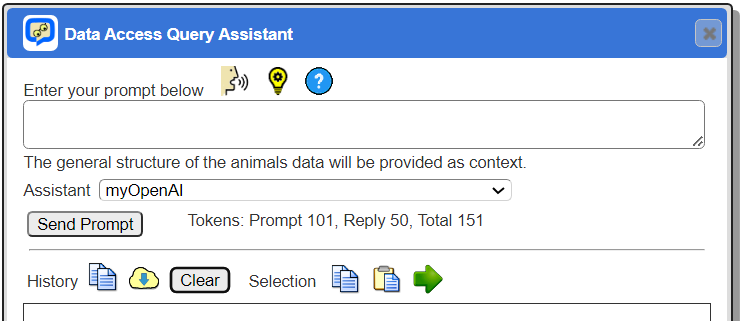
. . .

Manual Typing Input
Enter a prompt for the chat bot as shown below.
create a query to retrieve all of the animals sorted by type and age
The first prompt sent to the AI Assistant includes the type of database (i.e., MongoDB, SQL, etc.) plus data structure information for better context. Otherwise it does not have any information about the data being queried. Click

The prompt will be sent and Qarbine will wait for an Open AI reply. Statistics are shown.

Open AI’s service has restrictions as to the number of tokens. The default count is fixed at 2048 tokens, while the maximum can be set at 4096 tokens. Restricting the token usage can result in short answers, which might limit the output and impact your usage experience. Note that tokens are consumed by the API key’s organization and user interactions are logged for Qarbine administrator review. The AWS Bedrock service does not have this notion. Refer to your service’s documentation for details.
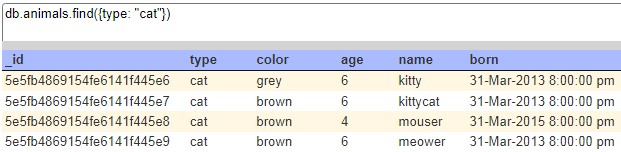
The bottom portion of the dialog shows the following in this example which is for a MongoDB database.

In this case, after reviewing you can copy the query from the results, paste it into the query field of the Data Source Designer and run it!
Below is a follow up example prompt.
Click .
The result statistics are shown below.

The resulting text is shown below.

Sometimes the AI service responds with a preformatted query snippet. Qarbine recognizes this and adds a pop up menu. Clicking on  shows the pop up menu.
shows the pop up menu.

The 2nd and 3rd options adjust the query input area of the Data Source Designer. The 3rd menu option also runs it! Choosing

results in updates to the Data Source Designer as shown below.
This is a very fast and convenient way to explore building queries with your data. When researching queries, you should always review the queries and consider limiting the number of documents\rows returned. Recall the Data Source Designer has an option to limit answer set sizes returned as well. This truncation is done after the answer set is returned from the source so it is best to have the query sent to the source specify any maximum element size.
When the does not appear next to a suggested query you can use the selection tool bar icons to perform the pop up menu options.

Simply highlight the text in the history and click the desired toolbar button.
Voice Input
This feature depends on your browser and Qarbine feature level.
To start voice input click  .
.
The icon will alternate between  and
and  while in listen mode.
while in listen mode.
When you are done click the flashing icon. It will turn to  .
.
Review the input for transcription errors.
If satisfied then click
.
The information in the manual input section above then applies to the history.
To provide further voice input click the icon.
A sample of 2 voice inputs is shown below.
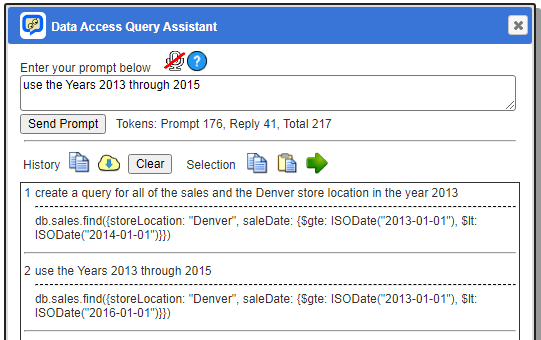
Managing History
Your prompts and the assistant’s replies are kept in the history area. Because of how many AI services are built, the history is sent along with your prompt for EACH AI Assistant interaction. Clearing the history resets the context. The data structure information will then be sent again to the AI service to provide that information for help in formulating a response.
You can copying the history text by clicking on  .
.
You can export the history text by clicking on  .
.
The dialog can be hidden by clicking on  . It can be reshown with its history intact etc. by clicking again in the Data Source Designer.
. It can be reshown with its history intact etc. by clicking again in the Data Source Designer.
Clicking the dialog’s  button closes out the dialog completely. Subsequent opening starts with a new history list.
button closes out the dialog completely. Subsequent opening starts with a new history list.
Plain English Query Explanations
You can also ask the query assistant to explain existing queries. For example, consider the query to retrieve data from the standard MongoDB mFlix sample data shown below.
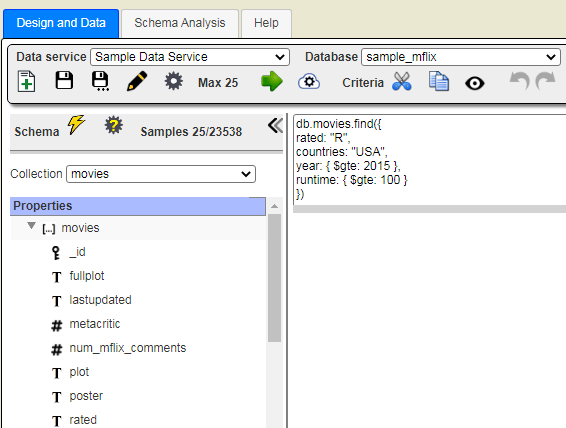
Open the AI Query Assistant by clicking  .
.
In the input field type ‘explain’.

Click

The result is shown below.
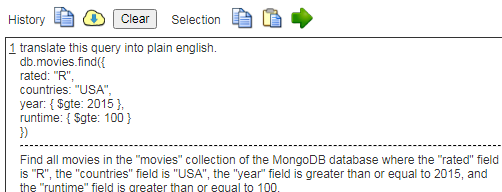
This is another way to use the power of AI to author and understand data queries.
Other Examples
Aggregated Criteria
With this collection

Consider this prompt.
the type of animal with the most number of occurrences
The AI Assistant responds with a proposed query and an explanation!
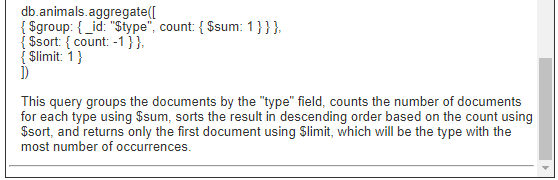
Running this in the Data Source Designer returns this result from MongoDB.

Slightly Abstract Math Reasoning Request
Consider this prompt.
create a query to determine which type has the most
The AI Assistant responds with


Clicking the menu dots and choosing  results in the query being copied over and then run as shown below.
results in the query being copied over and then run as shown below.

Summing a Field
Consider this prompt.
create a query that sums the ages of the animals
The AI Assistant responds with

Criteria and Sorting
Consider the MongoDB mFlix sample collection.

Consider this prompt.
retrieve the top 10 movies rated PG and released in the year 2013
sorted by imdb rating and title
The AI Assistant responds with


Note the IMDB rating is stored within an embedded document as shown below and the query above properly used dot notation to access it.

Embedded Simple Array
Consider this prompt.
retrieve 10 movies with an actor of “Harrison Ford”
The AI Assistant responds with

Embedded Document and Simple Array
Consider this prompt.
retrieve 10 movies with an actor of “Harrison Ford” that have an imdb rating of 7 or more
The AI Assistant responds with

Embedded Items and Display Fields
Consider this prompt.
retrieve 10 movies with an actor of “Harrison Ford” that have
an imdb rating of 7 or more and show the title, director, and actors
The AI Assistant responds with


Consider the prompt
create a query for all of the movies released between 2015 and 2017
that are R rated and have an imdb rating of at least 7
The AI Assistant responds with
…
To create a query for all movies released between 2015 and 2017 that are R rated
and have an IMDb rating of at least 7 in a MongoDB database with the movies
collection, you can use the following query:
javascript
db.movies.find({
released: {
$gte: ISODate("2015-01-01"),
$lte: ISODate("2017-12-31")
},
rated: "R",
"imdb.rating": {$gte: 7}
})
This query uses the `$gte` and `$lte` operators to match movies released between
January 1, 2015, and December 31, 2017. The `rated` field should have the value
"R" to match R-rated movies. The `imdb.rating` field should have a value greater than or
equal to 7 to match movies with an IMDb rating of at least 7.
You can execute this query using the MongoDB shell or any MongoDB driver for your chosen programming language.
Embedded Items, Display Fields and Sorting
Consider this prompt.
retrieve 10 movies with an actor of “Harrison Ford” that have
an imdb rating of 7 or more and show the title, director, and actors
sort by rating
The AI Assistant responds with

Compound Criteria Including Embedded Array Aggregated Criteria
Below is a portfolio collection structure.
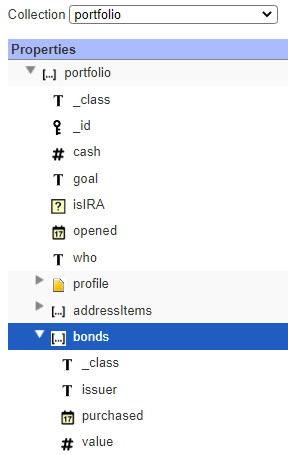
Consider this prompt.
create a query to return the portfolio with a cash value of 40000 or more
and a total bond value of 10000
The AI Assistant responds with

Note that the bonds are an embedded array within each portfolio document and the query performs the summation and filtering as well.
Possible Errors
The Open AI endpoint does have some rate limitations per minute which vary based on the type of account your organization has. Exceeding the rate limit may result in the errors such as those shown below.

If you exceed the maximum token input threshold for a model, OpenAI API throws 400. Same is the case with the models used. If you pass a wrong model name, OpenAI throws error 400. For more details see https://platform.openai.com/docs/guides/error-codes/api-errors.
These messages are common when hitting rate limits.

The other AI services have similar types of operating behaviors.
General References
https://www.mongodb.com/products/platform/atlas-vector-searchhttps://www.mongodb.com/developer/products/atlas/semantic-search-mongodb-atlas-vector-search/
https://www.mongodb.com/docs/atlas/atlas-vector-search/vector-search-overview/
https://www.together.ai/blog/rag-tutorial-mongodb
https://www.singlestore.com/blog/a-guide-to-retrieval-augmented-generation-rag/
https://dylancastillo.co/semantic-search-with-opensearch-cohere-and-fastapi/#vectorize-the-articles